Query 1B Rows in PostgreSQL >25x Faster with Squirrels!

The One Billion Row Challenge has been making waves in the data engineering community lately. Originally created to test CSV parsing performance, the challenge involves processing a file containing 1 billion weather measurements to calculate basic temperature statistics for each city. In this post, I'll tackle a variation of this challenge using PostgreSQL and demonstrate how to achieve dramatic performance improvements using Squirrels.
The Challenge
The original One Billion Row Challenge focuses on raw CSV processing performance. For our variation, we'll:
- Load 1 billion rows into PostgreSQL with additional columns
- Query for city-level temperature statistics
- Create a Squirrels project to serve these analytics via REST API
- Demonstrate significant query performance improvements
- Show how to handle incremental data updates
Setting Up the Environment
I provisioned the following AWS resources in the same region and availability zone:
- An RDS PostgreSQL database (db.r6g.large: 2 vCPUs, 16GB RAM)
- An EC2 instance (r8g.large: 2 vCPUs, 16GB RAM)
Data Generation and Loading
I generated a 24GB CSV file containing 1 billion weather measurements using a modified version of the createMeasurements.py script from this github repo. The first few lines of the file look like this:
Bissau;2012-02-20;14.3
Almaty;2019-10-24;-5.3
Ankara;2012-10-27;-6.7
Houston;2010-06-08;10.6
Makassar;2012-04-29;36.0
The data was loaded into a simple PostgreSQL table with the following DDL:
CREATE TABLE weather_data (
id SERIAL PRIMARY KEY,
city VARCHAR(100),
recorded_date DATE,
temperature FLOAT
);
This created a 73GB PostgreSQL table with 4 columns and 1 billion rows.
Initial Query Performance
Our baseline query to calculate city-level statistics:
SELECT city,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(temperature) AS avg_temperature
FROM weather_data
GROUP BY city
ORDER BY city;
This query took approximately 7 minutes to complete against the PostgreSQL table.
Enter Squirrels
I created a Squirrels project to serve these analytics via a REST API. The project structure looks like this:
sqrl-1brc-postgres/
├── models/
│ ├── dbviews/
│ │ ├── aggregate_weather.sql
│ │ └── aggregate_weather.yml
│ └── sources.yml
├── .gitignore
├── env.yml
├── requirements.txt
└── squirrels.yml
The query (found in models/dbviews/aggregate_weather.sql) was slightly modified to use Squirrels' source macro. A new column translate_test was added as well, which will be explained later.
SELECT city,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(temperature) AS avg_temperature,
(1::int / 2::int) AS translate_test
FROM {{ source("src_weather_data") }}
GROUP BY city
ORDER BY city;
The models/sources.yml file is used to tell Squirrels details about the source named "src_weather_data" including metadata about the table and columns.
The Squirrels project (the version from when this post was written) can be found on GitHub here:
This includes all files except for the env.yml file which looks something like this:
env_vars:
postgres_uri: postgresql://postgres:********@postgres-db.************.us-east-1.rds.amazonaws.com:5432/postgres
The project dependencies were installed using pip install -r requirements.txt. This also installs the sqrl CLI tool for commands such as running the API server and building the data artifact.
After running sqrl run --host 0.0.0.0 --no-cache to start the API server, the REST API can be accessed with GET method at the endpoint:
- /squirrels-v0/1brc-postgres/v1/dataset/aggregate-weather
By default, Squirrels includes a built-in result cache for the API results (where the cache's time-to-live can be configured). This was disabled by including the --no-cache flag in the sqrl run command.
Performance Results
First, I ran the API request without building the data artifact to get the baseline query performance. This was done 3 times before getting an average. Then, I ran sqrl build once to build the necessary data artifact to improve query performance, and I ran the API request 3 times again to observe the improvement. The data artifact is generated in the target/ folder and is about 5GB in size.
The following are the performance results:
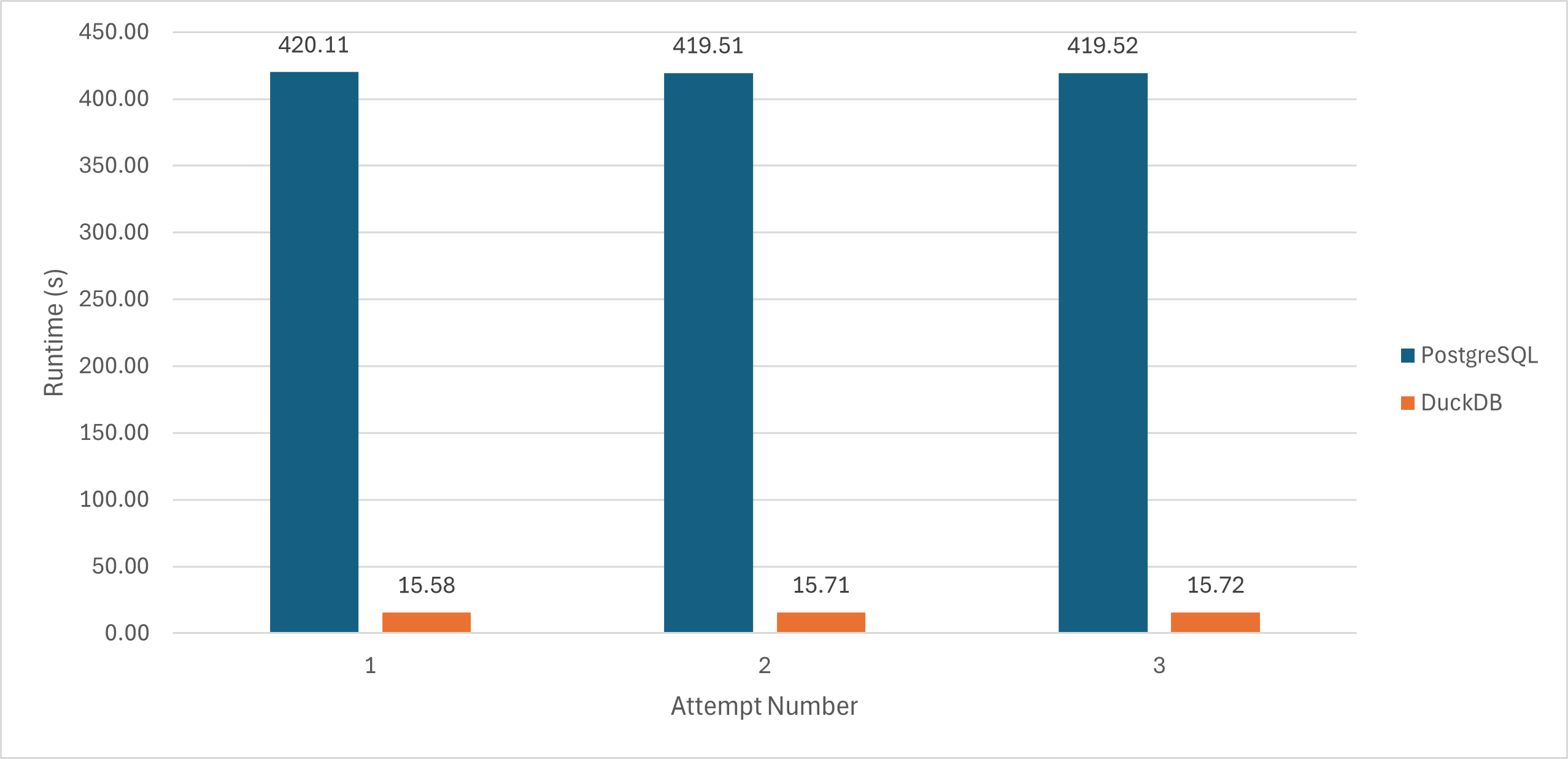
- Initial API Request (average of 3 runs): 419.71 seconds (≈7 minutes)
- Running
sqrl build: 434.19 seconds - API request after running the build (average of 3 runs): 15.67 seconds
We successfully reduced the query runtime from 7 minutes to 15.67 seconds, a 27x performance improvement!
As shown in the screenshot below, there was practically no difference in runtimes across the 3 runs.
With Squirrels, we can create pre-aggregated data models to improve query performance for specific queries. For instance, we can pre-aggregate the weather data by city and date to accommodate all queries that filter or group by city or date. With further modifications to the Squirrels project, this reduces the runtime of the query above to a fraction of a second! More details on this will be covered in Part 2.
Handling Data Updates
Squirrels makes it easy to handle incremental updates through update hints in sources.yml (notice the update_hints section below):
sources:
- name: src_weather_data
description: A table containing weather data
table: weather_data
update_hints:
increasing_column: id
columns: ...
To test this, I:
- Added 1 million new rows to the PostgreSQL table
- Ran
sqrl build --stage(took 41.84 seconds) and confirmed that the data artifact was updated - Tested query performance (took 15.66 seconds for 1.001 billion rows, similar to the 15.67 seconds for 1 billion rows)
The --stage flag ensures zero downtime during updates by staging the development copy before swapping the data artifact once it's not in use by any ongoing queries. In addition, the sqrl build command can be run in the background at some time interval (e.g. every 10 minutes or every hour depending on data freshness requirements) to keep the data artifact up to date.
Behind the Scenes of the "Data Artifact"
The "data artifact" is actually a DuckDB database file. The sqrl build command is able to build the source table(s) as DuckDB table(s) if the source table are from PostgreSQL, MySQL, or SQLite. When running an API request, Squirrels will determine whether all the necessary source tables exist in the DuckDB database for PostgreSQL, MySQL, or SQLite queries. If they do, it will translate the SQL query into DuckDB's SQL dialect (using SQLGlot) and run the query on the DuckDB file instead. To prove that the translation is in place, the column translate_test returns 0 because the PostgreSQL dialect does integer division. If the query was run in DuckDB without translating, the result would have been 0.5 because DuckDB does floating point division when dividing two integers using the / operator.
Support for loading from additional sources (e.g. APIs, S3, etc.) with sqrl build will be made available in the future.
Conclusion
Using Squirrels together with DuckDB, we achieved:
- 27x faster query performance on 1 billion rows without changing the PostgreSQL query
- Simple incremental updates with zero-downtime refreshes
While it is possible to optimize the PostgreSQL table for better performance, it often requires significant time and effort with only modest gains. In contrast, using Squirrels can achieve substantial performance improvements with minimal effort.
In Part 2, we'll explore dynamic parameterized queries that change based on user input for date ranges, and demonstrate how to join results from multiple databases and unstructured data from S3!